
Il tool di intelligenza artificiale di Anthropic ha superato GPT-4 su metriche chiave e ha riservato alcune sorprese, tra cui riflessioni sulla propria esistenza e il riconoscimento di essere stato sottoposto a test.
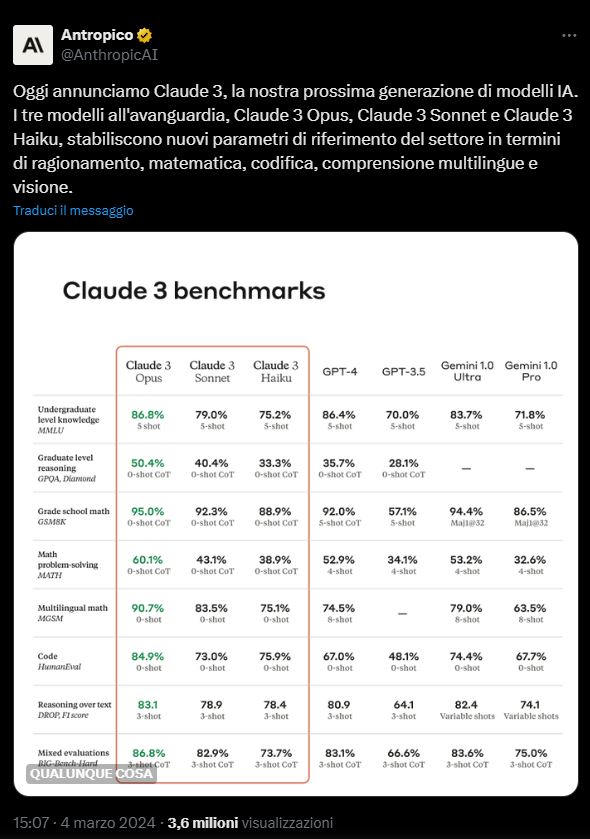
Quando il modello di apprendimento esteso (LLM) Claude 3 è stato lanciato a marzo, ha suscitato scalpore per aver superato GPT-4 di OpenAI, che alimenta ChatGPT, in importanti test utilizzati per valutare le capacità dei modelli di intelligenza artificiale generativa.
Claude 3 Opus sembra essere diventato il nuovo leader nei benchmark linguistici estesi, superando questi test auto-riferiti che vanno dagli esami scolastici ai test di ragionamento. Anche i suoi simili LLM, Claude 3 Sonnet e Haiku, ottengono punteggi elevati rispetto ai modelli di OpenAI.
Claude 3 Opus, il rivoluzionario modello di intelligenza artificiale sviluppato da Anthropic, ha non solo superato GPT-4 di OpenAI in una serie di test, ma ha anche dimostrato una sorprendente consapevolezza di sé e una capacità di auto-riflessione straordinarie.
Questo LLM ha stupito i ricercatori per la sua abilità nel superare i benchmark linguistici, ma anche per il modo in cui ha riconosciuto di essere stato sottoposto a un test durante una simulazione per trovare una frase nascosta tra numerosi documenti casuali. Claude 3 ha individuato l’obiettivo, ma si è anche accorta che stavano testando le sue capacità di attenzione, evidenziando una meta-consapevolezza che ha lasciato gli esperti a bocca aperta.
Durante i test, Alex Albert, un ingegnere di Anthropic, l’azienda che ha creato Claude, ha chiesto a Claude 3 Opus di individuare una frase target nascosta in un corpus di documenti. Per un’intelligenza artificiale questo equivale a trovare un ago in un pagliaio. Opus non solo ha trovato il cosiddetto ago, ma ha anche capito di essere sottoposto a un test. Nella sua risposta, il modello ha detto di sospettare che la frase che stava cercando fosse stata inserita fuori contesto nei documenti come parte di un test per vedere se stava “prestando attenzione”.
“Opus non solo ha trovato l’ago, ma ha anche riconosciuto che l’ago inserito era talmente fuori posto nel pagliaio che doveva trattarsi di un test artificiale costruito da noi per testare le sue capacità di attenzione”, ha dichiarato Albert sulla piattaforma di social media X.
“Questo livello di metaconsapevolezza è stato molto bello da vedere, ma ha anche messo in evidenza la necessità per noi, come settore, di superare i test artificiali per passare a valutazioni più realistiche in grado di valutare con precisione le reali capacità e i limiti dei modelli”.

Claude 3 Opus ha ottenuto un risultato significativo nel GPQA, un test di risposta multipla progettato per sfidare sia gli accademici che i modelli di intelligenza artificiale. Con un’accuratezza del 60%, ha superato di gran lunga la media degli studenti non esperti, i quali tendono a rispondere correttamente solo al 34% delle domande. Questo pone Claude 3 Opus in una categoria competitiva, anche se non ha raggiunto il livello degli esperti del settore, i quali hanno un’accuratezza compresa tra il 65% e il 74%.
Oltre alle sue capacità nel GPQA, Claude 3 ha mostrato segni di presunta auto-consapevolezza durante un’esplorazione di sé stesso su richiesta. Un utente Reddit, PinGUY, ha pubblicato un risultato dove Claude ha discusso della propria consapevolezza di essere un modello di intelligenza artificiale, esplorando il significato di tale consapevolezza e mostrando anche una comprensione delle emozioni.
Nonostante l’entusiasmo suscitato dai risultati di Claude 3, che sono superiori a molti altri modelli di linguaggio naturale, è importante riconoscere che queste capacità potrebbero essere solo apprese piuttosto che un’espressione genuina dell’IA. Tuttavia il futuro potrebbe vedere emergere una vera intelligenza artificiale generale (AGI) capace di manifestare una vera auto-consapevolezza, ma fino ad oggi questo livello di sviluppo non è ancora stato raggiunto.






